Data storage is a very crucial part for an application. There is actually no application where we need not to store data. So, an appropriate database selection is a very important before creating any application. This is where we store and fetch our user information, business information and also system information. But as our application user grows data grows too. The more data in a database the more time it needs to fetch, update or index data. If our database is not maintained or designed properly it may slow down application. There are various techniques you can apply to your database engine to overcome this issue but in my opinion the first step you can take is to shard/partition your database. So what is a database sharding?
According to educative.io,
Database sharding is the process of making partitions of data in a database or search engine, such that the data is divided into various smaller distinct chunks, or shards. Each shard could be a table, a Postgres schema, or a different physical database held on a separate database server instance.
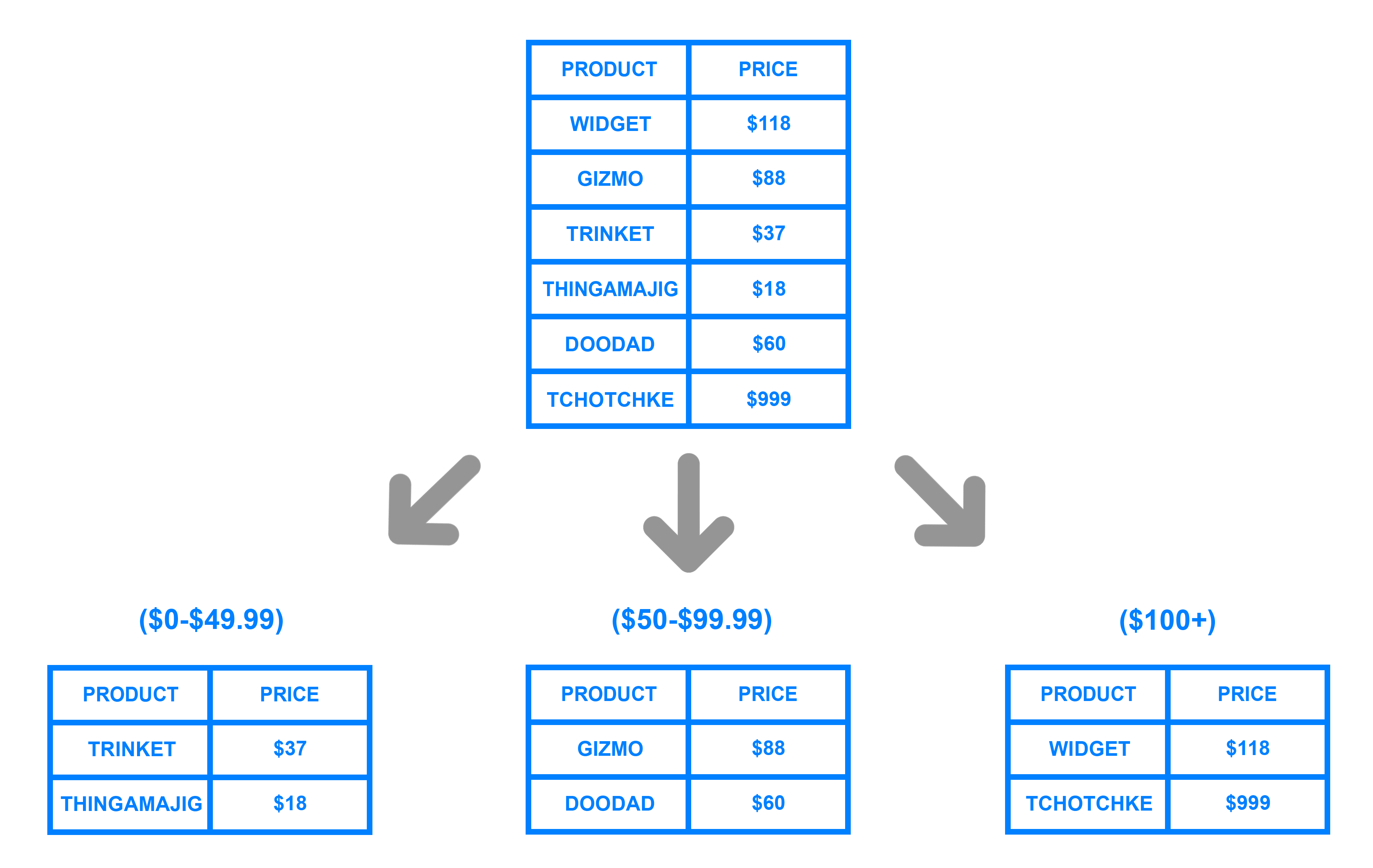
So the main idea is to distribute you data in different places and keep a track that which data is stored in where. As our database traverse data by row-column while querying, if we divide these data then the data access will be faster. There are various techniques to shard/partition your database. It depends on your application scenario. You can either distribute your table or create different database in multiple computers. Today we are going to explore how you can shard your PostgreSQL database and partition our database by table.
Postgres versions > 10 has a cool feature called Declarative Partitioning where you can partition your tables and PostgreSQL will manage it for you. As they have stated,
PostgreSQL allows you to declare that a table is divided into partitions. The table that is divided is referred to as a partitioned table. The declaration includes the partitioning method as described above, plus a list of columns or expressions to be used as the partition key.
For example, we can declare a partition while creating a table,
CREATE TABLE measurement ( city_id int not null, logdate date not null, peaktemp int, unitsales int ) PARTITION BY RANGE (logdate);
Here, we are creating a table by declaring a partition by a logdate. After declaring the partition we can then create our partition tables. So the next tables we are going to create are,
CREATE TABLE measurement_y2006m02 PARTITION OF measurement
FOR VALUES FROM ('2023-02-01') TO ('2023-03-01');
CREATE TABLE measurement_y2006m03 PARTITION OF measurement
FOR VALUES FROM ('2023-03-01') TO ('2023-04-01');
We have declared two tables for February 2023 and March 2023. When we insert a data Postgres will look at your logdate column data and store it in the appropriate month table. So when are querying for date 2023-03-12 data our database engine will only query measurement_y2006m03 table. This is how we shard a table in Postgres.
We can also do nested shards in Postgres. For example if we wanted to shard measurement_y2006m03 table with peaktemp then we should create our table by declaring the partition. For example,
CREATE TABLE measurement_y2006m03 PARTITION OF measurement
FOR VALUES FROM ('2006-02-01') TO ('2006-03-01')
PARTITION BY RANGE (peaktemp);
And next our new partition table for measurement_y2006m03 table would be,
CREATE TABLE measurement_y2006m03_0115 PARTITION OF measurement
FOR VALUES FROM (1) TO (15);
It would sub-partition our table for peaktemp values 1-15.
Okay, now how we would run our operations with these partitions? As we do always. We would query our master table only. Postgres will do the rest for us,
SELECT * from measurement;
Same goes for updating table schema, just on the master table and it will apply that change to all partitions,
ALTER TABLE measurement ADD COLUMN city_name TEXT NOT NULL;
There are 3 types of partition that Postgres offers:
- Range Partitioning
- List Partitioning
- Hash Partitioning
Read more on this: https://www.postgresql.org/docs/current/ddl-partitioning.html
Cool stuff! But there are limitations too!
- You can't ALTER a table to add partition later. It should be declared while you are creating a table. If you are using database migration frameworks like Entity Framework then it may not be possible to create a table with partition declaration.
- You have to manually create a partition table and if a new insert value doesn't match the range then Postgres will throw an error. But you can automate it. I'll write a post on how you can automate this table creation.
That's all for the sharding!